03 · 描述性统计与数据概览
一、描述性统计与数据概览
在做假设检验和建模之前,第一步总是:先弄清楚手里的数据“长什么样”。描述性统计(descriptive statistics)就是用简洁的数值和图形,把数据的整体面貌概括出来,为后续的推断和建模打基础。它主要围绕三个问题展开:
- 中心在哪里?——集中趋势:大多数数据落在什么水平?用均值、中位数等概括。
- 差异有多大?——离散程度:个体之间波动大不大?用标准差、四分位距等衡量。
- 形状是什么样?——分布形状:是否对称、是否偏态、有没有长尾?这会影响我们选用何种统计方法。
为了与第 02 章保持一致,本章也继续使用 MASS 包中的恶性黑色素瘤数据集 Melanoma 作为例子,直接在第 02 章构造/清洗过的数据基础上做“描述”。在 R 中,只需加载 MASS 包并执行 data(Melanoma) 即可获得同样的数据。本章所有代码和图表都基于这份数据,读者可以一边对照文字一边在 R 里复现。
1.1 例子数据集:Melanoma
Melanoma 是一个经典的恶性黑色素瘤(皮肤肿瘤)随访队列数据集,来源于历史临床随访研究,每一行是一位患者的记录。理解每个变量的含义,有助于在后续做描述和建模时选择正确的指标与图表。主要字段含义如下(与第 02 章使用的是同一份数据):
time:随访时间,一般以“天(days)”计,从手术切除到结局(死亡或随访截止)的时间长度。status:结局状态,常见编码为 0=仍存活/随访中,1=死于黑色素瘤,2=死于其他原因。在做生存分析或描述性统计时,常需要区分“肿瘤相关死亡”和“非肿瘤死亡”。sex:性别,原始数据中为 1=男性、0=女性。在第 02 章中,我们曾把该变量标准化为“男/女”编码,这里只要知道它代表患者性别即可。age:手术时年龄,单位为岁,是后续描述和建模中最常用的连续变量之一。year:手术年份,比如 1970、1971 等,可以用于考察不同年代诊疗水平变化。thickness:肿瘤厚度(Breslow thickness),是恶性黑色素瘤预后最重要的连续型指标之一,数值越大往往提示肿瘤更加进展、预后更差。ulcer:是否存在溃疡(0=无,1=有),是一个 0/1 分类变量,溃疡常被视为不良预后因素。
在后文的所有代码示例中,如果未特别说明,都可以理解为在 Melanoma 上进行的描述性统计或预处理。当你自己做项目时,只需把 Melanoma 换成自己的数据框,把 thickness、age 等变量名替换成项目里的实际字段名,代码结构即可复用。
# 载入 MASS 包并加载 Melanoma 数据
options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
install.packages("MASS") # 如果已安装会提示跳过
library(MASS)
data(Melanoma)
head(Melanoma)
summary(Melanoma)1.2 为什么要先“描述”再建模
跳过描述性统计、直接跑检验或拟合模型,是很多初学者容易犯的习惯性错误。先做描述有两方面的实际价值:
- 直接套用检验/模型,可能在严重偏态、极端值很多的数据上得出“看起来显著”的错误结论。
- 描述性统计帮你发现:中心在哪里、数据是否合理、是否存在可疑值或分层结构,避免把异常数据当成“真信号”。
- 根据分布形状决定用均值±标准差还是中位数(IQR)来报告。
- 根据是否近似正态决定用 t 检验还是非参数检验。
- 根据量纲和偏态决定是否需要对数变换或标准化,再进入建模。
1.3 变量类型与合适的指标
变量类型决定了“能算什么、该怎么报”。选错指标不仅会让审稿人质疑,也可能误导临床解读。不同类型的变量,适合的描述指标大致如下:
二、描述数据的“集中趋势”
集中趋势回答的是“数据大致集中在哪个水平”,是读者和审稿人最常扫一眼的概括指标。报告时选对指标很重要:近似正态时用均值更直观,明显偏态时用中位数更稳妥。常用的三个指标是:平均数、中位数、众数。
2.1 平均数、中位数、众数
- 平均数(mean):所有观测值相加除以个数,含义直观,但对极端值异常敏感,一个特别大的离群值就能把均值“拉偏”。
- 中位数(median):排序后正中间的值(或中间两数的平均),对偏态和极端值更稳健,医学论文里偏态变量常以中位数报告。
- 众数(mode):出现次数最多的取值,常用于分类变量或等级变量,例如“最常见的分期是 II 期”。
在 Melanoma 中,可以把 thickness 理解为一个典型的连续变量,把 sex 或 ulcer 理解为分类变量。下面的代码示例中,我们用肿瘤厚度 thickness 来计算均值和中位数,用 sex 来演示众数的概念;实际分析时建议先画直方图看分布,再决定以均值还是中位数为主来报告。
library(MASS)
data(Melanoma)
# 以肿瘤厚度 thickness 为例(连续变量)
x <- Melanoma$thickness
mean(x) # 平均数
median(x) # 中位数
# 众数:适用于分类变量,这里示例性别 sex
get_mode <- function(v) {
tb <- table(v)
names(tb)[which.max(tb)]
}
get_mode(Melanoma$sex)2.2 医学场景下如何报告
在医学论文或研究报告中,描述性统计通常出现在“基线特征表”(常被称作 Table 1)中,用于说明研究对象的整体情况,便于读者判断样本是否具有代表性、与既往研究是否可比。对于恶性黑色素瘤这样的肿瘤队列,最常见的变量包括年龄、肿瘤厚度、是否溃疡以及性别、结局状态等。
不同变量类型和分布形态,对应不同的报告规范。常见的写法有:
- 近似正态的连续变量:报告“均值 ± 标准差”(例如:年龄 56.2±8.4 岁)。
- 偏态分布的连续变量:报告“中位数(IQR)”(例如:住院天数 7(4, 12)天)。
- 分类变量:报告“频数(比例)”(例如:男性 60 例(55.6%))。
对 Melanoma 而言,可以像下面这样先计算厚度的均值/标准差与中位数/IQR,然后再用 sprintf() 拼成论文中常见的呈现格式:
# 用 Melanoma 构造类似“表 1”中的一行
library(MASS)
data(Melanoma)
# 以 thickness 为例
x <- Melanoma$thickness
mean_SL <- mean(x); sd_SL <- sd(x)
med_SL <- median(x); iqr_SL <- IQR(x)
sprintf("thickness: %.2f ± %.2f mm", mean_SL, sd_SL)
sprintf("thickness: %.2f (%.2f, %.2f)",
med_SL,
quantile(x, 0.25),
quantile(x, 0.75))三、描述数据的“离散程度”
离散程度回答“数据之间差异有多大”。只报告中心而不报告离散,信息是不完整的:同样的平均值,离散程度不同,在临床上可能意味着完全不同的稳定性和异质性。例如,两个黑色素瘤队列平均厚度都为 2 mm,但一组厚度非常集中在 1.5–2.5 mm,另一组从 0.2 mm 到 10 mm 都有,那么后者的病情异质性显然更大,治疗和预后判断也需要更个体化。
3.1 极差、方差与标准差
- 极差(Range):最大值 − 最小值,最直观,但受极端值影响极大,一个离群值就会把极差撑得很大。
- 方差(Variance):每个值相对平均数的平方偏差的平均,单位是原变量的平方,数值往往较大,不便于直接解读。
- 标准差(SD):方差的平方根,单位与原变量相同,在论文中最常与均值搭配使用,表示“典型偏离均值的幅度”。
# 仍以 thickness 为例
library(MASS)
data(Melanoma)
x <- Melanoma$thickness
max(x, na.rm = TRUE) - min(x, na.rm = TRUE) # 极差
var(x, na.rm = TRUE) # 方差
sd(x, na.rm = TRUE) # 标准差3.2 四分位距与变异系数
- 四分位距(IQR):Q3 − Q1,反映中间 50% 数据的范围,不受两端极端值影响,比极差稳健;偏态分布时常用“中位数(IQR)”一起报告。
- 变异系数(CV):\(CV = sd/mean\),即标准差与均值的比,无量纲,用于比较不同量纲、不同均值的变量之间的相对离散程度(例如比较年龄与肿瘤厚度的波动谁更大)。
library(MASS)
data(Melanoma)
x <- Melanoma$thickness
IQR(x, na.rm = TRUE)
q <- quantile(x, c(0.25, 0.5, 0.75), na.rm = TRUE)
q
cv <- sd(x, na.rm = TRUE) / mean(x, na.rm = TRUE)
cv3.3 医学例子中的“波动解读”
在结果部分写“均值±标准差”或“中位数(IQR)”时,不仅要报数字,也要能从临床角度简单解读离散程度。同样的平均值,标准差或 IQR 不同,在医学上的含义可能截然不同:
- 血压均值 130 mmHg,标准差 5 vs 25:前者说明多数患者血压控制较稳定,后者可能提示血压控制不良、测量不规范或人群异质性大,需要进一步分层或排查。
- 在 Melanoma 中,如果两组患者的肿瘤厚度均值都约为 2 mm,但一组 IQR 为 1.5–2.5 mm,另一组 IQR 为 0.5–6.0 mm,则后者包含了更多“极薄”和“极厚”的肿瘤亚型,治疗策略和预后判断都需要更加谨慎,单纯比较两组均值可能掩盖重要差异。
四、描述数据的“分布形状”
分布形状不仅影响我们“用均值还是中位数”来描述,还直接决定后续推断方法能否使用——例如 t 检验、方差分析等参数方法更适合近似正态的数据,而明显偏态时往往需要非参数方法或先做变换。在 Melanoma 中,thickness 和 time(随访时间)往往呈现明显的右偏分布:多数患者厚度较小、生存时间较长,少数患者厚度很大或很早发生事件,形成长尾。这种形态在生存数据与肿瘤指标中非常常见。
4.1 偏度与峰度
- 偏度(Skewness):衡量分布的不对称性。偏度 > 0 为右偏(右侧长尾),< 0 为左偏;接近 0 时分布大致对称。医学数据里很多连续变量是右偏的。
- 峰度(Kurtosis):衡量分布相比正态分布是更尖还是更平、尾部更厚还是更薄。正态分布的峰度约为 3,大于 3 表示尾部更厚、极端值更多。
skewness <- function(v) {
v <- v[is.finite(v)]
m <- mean(v); s <- sd(v)
mean((v - m)^3) / (s^3)
}
kurtosis <- function(v) {
v <- v[is.finite(v)]
m <- mean(v); s <- sd(v)
mean((v - m)^4) / (s^4)
}
library(MASS)
data(Melanoma)
skewness(Melanoma$thickness)
kurtosis(Melanoma$thickness)4.2 频数/频率分布与分箱
对连续变量,除了算均值和标准差,还可以通过分箱(把连续值划成若干区间)得到频数表或频率表,从而用“每个区间有多少人、占多少比例”来概括分布,有时比单一数字更直观。
library(MASS)
data(Melanoma)
x <- Melanoma$thickness
bins <- cut(x, breaks = 8)
freq <- table(bins)
freq
prop.table(freq)分箱数量过少,细节会丢失;过多则会显得杂乱,且每个区间样本量过小不稳定。一般 8–15 个箱是常见的起点,具体需结合样本量和数据范围调整;也可以按临床有意义的切点(如肿瘤厚度 1 mm、4 mm)来分箱。
4.3 分布形状与后续方法选择
看完分布形状后,可以据此决定用哪类指标和检验:
- 近似对称、单峰:可考虑使用均值±SD 描述,t 检验、方差分析等参数方法一般可用。
- 明显偏态、长尾、多峰:更适合报告中位数(IQR),并考虑对数变换使分布更对称,或直接采用非参数方法(如 Wilcoxon 检验)。
- 多峰分布:可能提示混合人群(例如不同疾病亚型混在一起),可尝试分层分析或聚类,再在各层内单独描述。
五、数据变换与预处理
前面几节主要是在“原始尺度”上描述数据的中心、差异和分布形状。在实际分析中,我们经常会先对数据做一些变换或预处理,再去画图、做检验或建模——例如把偏态变量取对数后再做 t 检验,或把多个量纲不同的变量标准化后再放进同一模型。本节重点介绍几类常见变换:
- 对连续变量做缩放/标准化(如 min-max 归一化、z-score 标准化),使不同量纲的变量可比;
- 对偏态分布做对数/平方根等非线性变换,使分布更接近对称;
- 把连续变量离散化成若干临床上更好解释的分组(如年龄分段、厚度分层);
- 对分类变量做独热编码/哑变量编码,为回归和机器学习建模做准备。
所有示例仍然基于 Melanoma 数据集,你在自己的项目中只需把变量名替换成实际字段名即可。
5.1 为什么要做数据变换
数据变换不是“为了好看”,而是为了解决分析中的具体问题,大致有四类常见动机:
- 让不同量纲的变量可比:例如把年龄(岁)、肿瘤厚度(mm)、实验室指标(mg/dL)放进同一个模型时,需要做标准化,避免某个量纲过大的变量主导结果。
- 减弱严重偏态和长尾:例如对肿瘤厚度、住院天数做对数变换,使分布更接近对称,方便使用参数方法。
- 把难以直接解释的连续变量变成临床上更熟悉的分层:例如按年龄分为“<40 岁、40–60 岁、>60 岁”。
- 把类别信息编码成数值:许多模型只能接收数值输入,需要把“男/女、是否溃疡”等变量转换成 0/1 哑变量。
5.2 常见数值变换:标准化与对数
这里选取 thickness 作为示例,演示 min-max 归一化、z-score 标准化和对数变换三种方式,并在后面用一行四列的直方图对比变换前后的分布形态。实际使用时,可根据分析目的选择其一或组合使用(例如先取对数再标准化)。
library(MASS)
data(Melanoma)
x_raw <- Melanoma$thickness
# 1)min-max 归一化到 [0, 1]
x_minmax <- (x_raw - min(x_raw, na.rm = TRUE)) /
(max(x_raw, na.rm = TRUE) - min(x_raw, na.rm = TRUE))
# 2)z-score 标准化:减去均值、除以标准差
x_z <- scale(x_raw) # 返回矩阵,可用 as.numeric() 转成向量
# 3)对数变换:常用 log 或 log1p
x_log <- log(x_raw) # 适用于全部 > 0 的情况
x_log1p <- log1p(x_raw) # log(1 + x),对接近 0 的值更稳健用公式来写,这几类变换可以概括为:
- min-max 归一化:把原始取值 \(x\) 映射到 \([0,1]\) 区间 \[ x^{\ast} = \frac{x - \min(x)}{\max(x) - \min(x)} \]
- z-score 标准化:以均值 \(\mu\) 为中心、按标准差 \(\sigma\) 缩放 \[ z = \frac{x - \mu}{\sigma} \] 得到的 \(z\) 一般具有均值约为 0、标准差约为 1 的分布。
- 对数变换:适用于 \(x > 0\) 且右偏、长尾分布的情形
\[
y = \log(x), \quad \text{或} \quad y = \log(1 + x)
\]
其中 \(\log(1 + x)\)(R 中的
log1p(x))在 \(x\) 接近 0 时数值更稳定。
为了直观比较四种形态,可以把原始值、min-max、z-score 和 log1p 变换后的值画在同一行直方图中,这样能一眼看出:归一化后数据挤在 [0,1]、标准化后大致以 0 为中心、对数变换后右偏会明显减弱。
library(MASS)
data(Melanoma)
x_raw <- Melanoma$thickness
x_minmax <- (x_raw - min(x_raw, na.rm = TRUE)) /
(max(x_raw, na.rm = TRUE) - min(x_raw, na.rm = TRUE))
x_z <- as.numeric(scale(x_raw))
x_log1p <- log1p(x_raw) # 使用 log(1 + x) 避免对 0 出问题
par(mfrow = c(1, 4))
hist(x_raw,
breaks = 15,
main = "原始 thickness",
xlab = "mm")
hist(x_minmax,
breaks = 15,
main = "min-max 归一化",
xlab = "归一化后数值")
hist(x_z,
breaks = 15,
main = "z-score 标准化",
xlab = "标准化后数值")
hist(x_log1p,
breaks = 15,
main = "log1p(thickness)",
xlab = "log1p(mm)")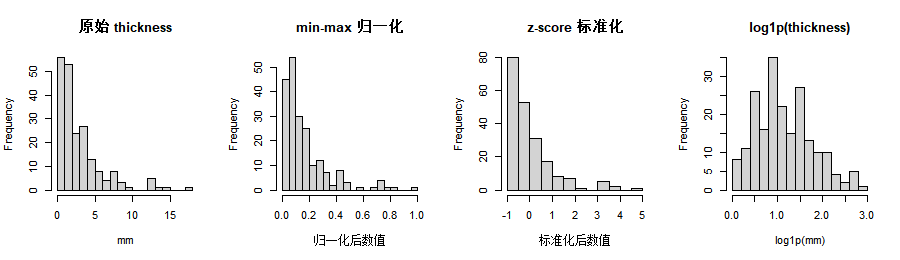
使用场景小结:
- min-max 归一化:适合需要把特征限制在固定区间(如 [0,1])的算法,例如神经网络、K 近邻、基于距离的聚类等;缺点是受极端值影响大,若存在离群值,其余数据会挤在很窄的区间内。
- z-score 标准化:在回归、主成分分析、LASSO 等方法中非常常见,系数可解释为“每 1 个标准差变化”带来的效应;新数据预测时需用训练集的均值和标准差来变换,保证与训练阶段一致。
- log/log1p 变换:对右偏、长尾且值均为正的变量(如厚度、随访时间、住院天数、某些实验室指标)特别常用;若数据含 0,建议用
log1p避免 \(\log(0)\) 无定义。
5.3 离散化:把连续变量变成分组
在医学论文里,很多连续变量最终会以“分组”的形式出现在表格和图中,这样更便于临床理解和与指南对照。常见的分组方式例如:
- 年龄:<40 岁、40–60 岁、>60 岁;
- 肿瘤厚度:≤1 mm、>1–4 mm、>4 mm(与 AJCC 分期类似);
- 实验室指标:按四分位数分成 Q1–Q4 四组。
在 R 中,可以用 cut() 指定区间端点,或用 quantile() 按分位数自动切分,再配合 table()、barplot() 等得到分组频数和条形图。下面给出按临床阈值和按四分位数分组的两种示例。
library(MASS)
data(Melanoma)
x <- Melanoma$thickness
# 例 1:按临床常用阈值分组(这里举例:≤1, 1–4, >4 mm)
grp_clinical <- cut(
x,
breaks = c(-Inf, 1, 4, Inf),
labels = c("<=1 mm", "1-4 mm", ">4 mm")
)
table(grp_clinical)
# 例 2:按四分位数分成 Q1–Q4
qs <- quantile(x, probs = c(0, 0.25, 0.5, 0.75, 1), na.rm = TRUE)
grp_q <- cut(
x,
breaks = qs,
include.lowest = TRUE,
labels = c("Q1", "Q2", "Q3", "Q4")
)
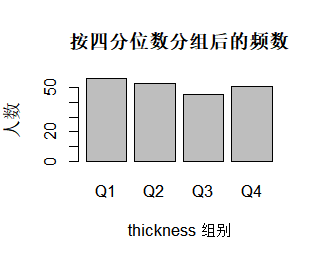
table(grp_q)# 对比分组前后的分布:原始 thickness vs 四分位组别
library(MASS)
data(Melanoma)
x <- Melanoma$thickness
qs <- quantile(x, probs = c(0, 0.25, 0.5, 0.75, 1), na.rm = TRUE)
grp_q <- cut(
x,
breaks = qs,
include.lowest = TRUE,
labels = c("Q1", "Q2", "Q3", "Q4")
)
par(mfrow = c(1, 2))
hist(x,
breaks = 15,
main = "原始 thickness 分布",
xlab = "thickness (mm)")
barplot(table(grp_q),
main = "按四分位数分组后的频数",
xlab = "thickness 组别",
ylab = "人数")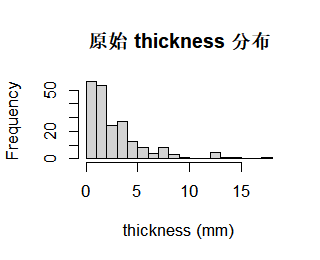
使用场景小结:离散化在结果展示和临床解释上非常友好,审稿人和临床医生也习惯看分层结果。但离散化会损失一部分信息,做预测或因果推断建模时,一般应优先考虑保留连续形式;仅在需要与临床分层一致、或做敏感性分析时,再对连续变量做分组。
5.4 独热编码与哑变量
对于有多个类别的分类变量(例如:治疗方案 A/B/C,分期 I/II/III/IV),回归和多数机器学习模型无法直接使用“类别名”,需要转换成数值。常见的两类编码方式:
- 独热编码(one-hot):每个类别对应一个 0/1 变量,同一行中这些变量只有一个为 1、其余为 0,所有变量之和为 1。类别数较多时,变量会变多。
- 哑变量编码:在独热编码的基础上,去掉一个类别作为参考组,其余类别用 0/1 变量表示。这样既保留“与参考组对比”的信息,又避免完全共线性(即“虚拟变量陷阱”),回归系数可直接解释为“相对参考组”的差异。
在 R 中,用 model.matrix() 配合因子变量即可自动生成哑变量(默认以各因子的第一个水平为参考);也可使用 fastDummies 等包。下面用 sex 和 ulcer 作为简单示例:
library(MASS)
data(Melanoma)
df <- Melanoma
df$sex <- factor(df$sex, levels = c(0, 1), labels = c("F", "M"))
df$ulcer <- factor(df$ulcer, levels = c(0, 1), labels = c("no", "yes"))
# 使用 model.matrix 自动生成哑变量(去掉截距列)
mm <- model.matrix(~ sex + ulcer, data = df)[, -1]
head(mm)生成哑变量后,若你希望可视化不同类别组合的分布,可以像前面第六章一样画并列条形图或分组箱线图,例如查看“性别 × 溃疡”四种组合在肿瘤厚度上的差异,再与回归结果相互印证。
六、常用图表
数值指标回答“多少”,图形回答“长什么样”;两者结合,才能在汇报和论文中把数据讲清楚。图表还能帮助发现异常值、偏态和分组差异,是描述性统计不可或缺的一部分。实际写论文或做汇报时,常见的套路是:
- 先用 1–2 个总览图(如直方图、箱线图)快速传达“这个队列大概是什么水平”;
- 再用若干配套图(散点图、分组箱线图、条形图等)回答“不同亚组有没有明显差异”“是否存在极端病例”之类的具体问题;
- 最后把关键结论凝练成 1–2 句文字描述,直接写进结果部分。
在 Melanoma 这样的肿瘤队列中,我们往往会同时画出肿瘤厚度、年龄、随访时间的直方图和箱线图,并配合条形图展示性别、溃疡等分类变量的分布。如果你在做自己的项目,可以把下面所有代码中的变量名替换成你实际的数据字段,图形结构基本保持不变。
6.1 直方图与密度曲线
直方图把连续变量按区间划分成若干柱,柱高表示频数(或频率),适合展示分布形状、是否对称、是否有长尾或多峰。对 Melanoma 来说,thickness 的直方图可以帮助我们快速判断肿瘤厚度是否右偏、是否存在明显的长尾,从而决定用均值还是中位数来报告。在直方图上叠加密度曲线(lines(density(...)))可以更平滑地看出分布的形态。
在科研实践中,一个非常实用的小技巧是:同一篇文章中,尽量使用相似的横轴范围和分箱设置。比如你想同时展示厚度和年龄这两个变量的直方图,就可以把它们排成一行,方便读者直接比较“厚度是否比年龄更偏态”。
library(MASS)
data(Melanoma)
x <- Melanoma$thickness
hist(x, breaks = 15,
main = "Melanoma 肿瘤厚度直方图",
xlab = "thickness (mm)")
lines(density(x, na.rm = TRUE), col = "red", lwd = 2)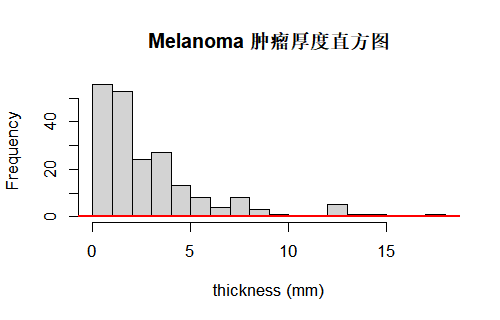
# 同一画布上放置两个直方图:厚度 vs 年龄
library(MASS)
data(Melanoma)
par(mfrow = c(1, 2))
hist(Melanoma$thickness,
breaks = 15,
main = "肿瘤厚度 thickness",
xlab = "mm")
hist(Melanoma$age,
breaks = 15,
main = "年龄 age",
xlab = "years")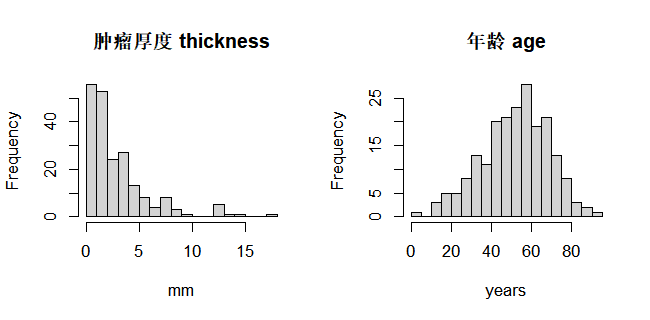
6.2 箱线图与异常值
箱线图用“箱体”表示 Q1–Q3 的范围,箱内的线表示中位数,两端的“须”通常延伸到 1.5×IQR 内的最值,之外的点单独标出作为潜在异常值。一张图就能同时看到中心、离散程度和离群值,比单纯的均值±标准差更稳健。在 Melanoma 中,我们可以分别画出厚度和年龄的箱线图,直观感受是否存在极端患者,再决定是否在后续分析中做敏感性分析或剔除。
当研究问题涉及“分组比较”时,可以把箱线图按组排在一起,例如按是否有溃疡、按性别或按治疗方案分层。一张分组箱线图,往往就能直观展示“哪一组更高、哪一组波动更大、组间是否有重叠”,非常适合放在结果部分靠前的位置,作为表格的补充。
library(MASS)
data(Melanoma)
par(mfrow = c(1, 2))
boxplot(Melanoma$thickness,
main = "肿瘤厚度 thickness",
ylab = "mm")
boxplot(Melanoma$age,
main = "年龄 age",
ylab = "years")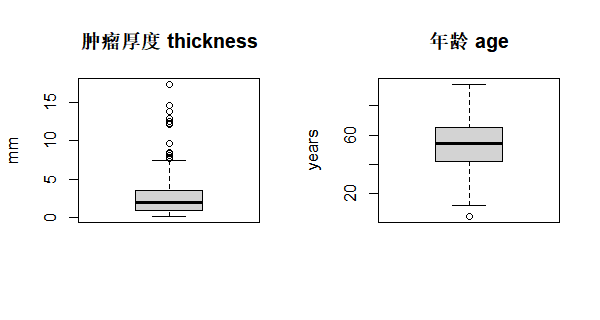
# 按是否存在溃疡分组的厚度箱线图
library(MASS)
data(Melanoma)
boxplot(thickness ~ ulcer,
data = Melanoma,
xlab = "ulcer (0=无, 1=有)",
ylab = "thickness (mm)",
main = "按溃疡分组的肿瘤厚度")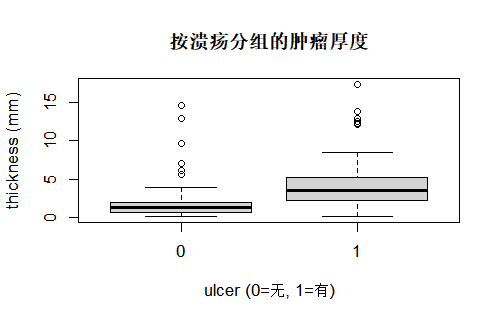
6.3 散点图与关系探索
散点图把两个连续变量分别放在横轴和纵轴,每个样本一个点,适合探索两变量之间是否有线性或非线性关系、是否有离群点、不同亚组是否呈现不同模式。例如,在 Melanoma 中可以绘制肿瘤厚度与随访时间的散点图,观察“更厚的肿瘤是否更容易在随访早期发生事件”(若存在负相关或某区域点密度不同,可为进一步的生存分析提供直观依据)。
散点图还可以叠加第三个变量的信息:比如用不同颜色或点型表示是否溃疡、是否死亡或性别,从而在一张图上同时呈现“厚度—时间—结局(或亚组)”的大致关系。正式写论文时,常见做法是:先给出简单的二元散点图,再根据需要补充分组着色或拟合趋势线、置信带。
library(MASS)
data(Melanoma)
plot(Melanoma$thickness, Melanoma$time,
xlab = "thickness (mm)",
ylab = "follow-up time (days)",
main = "散点图:厚度 vs 随访时间")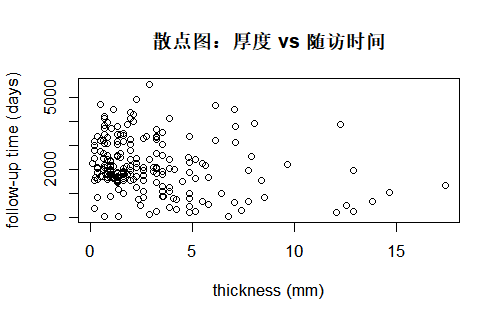
# 加入第三个变量:用颜色区分是否溃疡
library(MASS)
data(Melanoma)
cols <- ifelse(Melanoma$ulcer == 1, "red", "blue")
plot(Melanoma$thickness, Melanoma$time,
xlab = "thickness (mm)",
ylab = "follow-up time (days)",
main = "厚度 vs 随访时间(按溃疡分色)",
col = cols, pch = 19)
legend("topright",
legend = c("ulcer = 0", "ulcer = 1"),
col = c("blue", "red"),
pch = 19)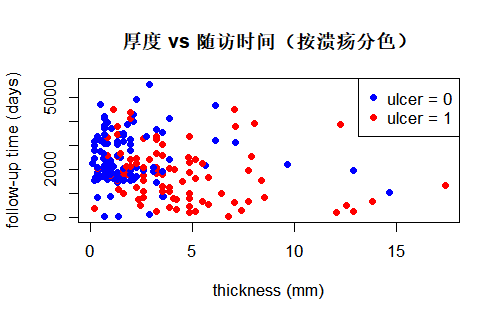
6.4 条形图 / 饼图(分类数据)
对于分类变量(如性别、是否溃疡、结局状态),常用频数或比例来概括,图形上条形图通常比饼图更易于比较各类别的大小——人眼对长度比对角度的差异更敏感。在 Melanoma 中,我们可以用条形图快速查看性别分布和溃疡发生情况,便于在 Table 1 之外再给读者一个直观印象。
如果想在同一张图中比较两个分类变量(例如“性别 × 溃疡”),可以使用堆叠条形图(看构成比)或并列条形图(看各类别频数并排对比)。对于医学读者来说,并列条形图往往更容易解读——可以直接看到“在男性和女性中,溃疡比例是否有明显差异”,便于与卡方检验或分层分析的结果对应。
library(MASS)
data(Melanoma)
tb_sex <- table(Melanoma$sex)
tb_ulcer <- table(Melanoma$ulcer)
par(mfrow = c(1, 2))
barplot(tb_sex, main = "性别分布", xlab = "sex", ylab = "人数")
barplot(tb_ulcer, main = "溃疡情况", xlab = "ulcer", ylab = "人数")
# 性别 × 溃疡 的并列表格和条形图
library(MASS)
data(Melanoma)
tab_sex_ulcer <- table(Melanoma$sex, Melanoma$ulcer)
tab_sex_ulcer
barplot(tab_sex_ulcer,
beside = TRUE,
legend.text = c("sex = 0 (女)", "sex = 1 (男)"),
args.legend = list(x = "topright"),
xlab = "ulcer (0=无, 1=有)",
ylab = "人数",
main = "性别 × 溃疡 并列条形图")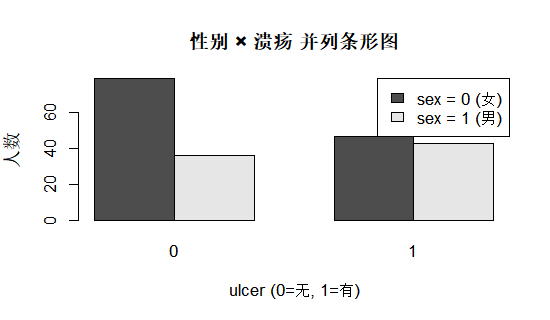
七、小结与练习
本章从“中心”“差异”“形状”三个角度系统介绍了描述性统计,并介绍了常用的数据变换(标准化、对数、离散化、哑变量)以及直方图、箱线图、散点图、条形图等图表。掌握这些内容后,你可以在拿到一份新数据时,先做一轮完整的描述与可视化,再根据分布形态和变量类型选择合适的报告方式和后续推断方法,避免“黑箱”分析和误用参数方法。
- 选取
iris中任意一个数值变量,计算其均值/中位数/极差/SD/IQR,并画直方图和箱线图;用 2–3 句话描述它的“中心、差异、形状”。 - 用
mtcars比较自动/手动(am)两组的mpg:分别画直方图和箱线图,并讨论哪一组的油耗更稳定。 - 任选一个研究问题(例如“不同性别的某指标是否不同”),写出你会在“结果”部分如何用描述性统计 + 图表来呈现基线情况。